.png)
云计算有无数的好处。它使组织能够通过远程访问以极低的价格获得最高质量的服务器和设备,而不是承担最新技术的全部成本。云计算使组织能够使用数据存储的实用模型,为他们使用的内容付费,而不必猜测和超支存储容量。它还包括跨分布式地理购买冗余的选项,这可以提高不同位置的最终用户的速度。
一、网络延迟
网络延迟的一个常见原因是云服务器和用户请求设备之间的地理距离请求必须经过。虽然此问题同样发生在云和本地网络中,但有一些简单的解决方案可以减少延迟。
1、边缘计算
一种解决方案是边缘计算,它使用基于用户地理位置的服务器。
2、多云架构
当一家云供应商无法提供与其员工足迹相匹配的数据中心位置时,组织还可以引入多云解决方案。在与用户位置一致的数据中心之间分配工作负载可以创建更快的连接,减少延迟,并在连接超时或链路饱和时增加切换路径的冗余。
3、升级网络路径或设备
尽管云以按使用量付费的结构提供无限且可扩展的容量,但在迁移期间或创建备份时将初始数据传输到云中的路径仍然受网络路径容量的影响。
如果传输介质是铜缆,则与数据传输介质是光缆相比,您的容量将受到更多限制。路由器也可能是无法在不丢失数据包的情况下处理大量数据的最薄弱环节。
4、使用“Sneakernet”进行大型数据转储
避免过度配置电路的一种选择是将数据备份通过磁带或光盘发送到云数据中心,以便云提供商直接上传。通过光盘或其他设备手动复制和传输文件的方式称为“sneakernet”。
5、看看是否有效
您可以在命令界面中使用 ping 或 netperf 命令检查延迟。大多数网络监控工具都包含延迟计算。
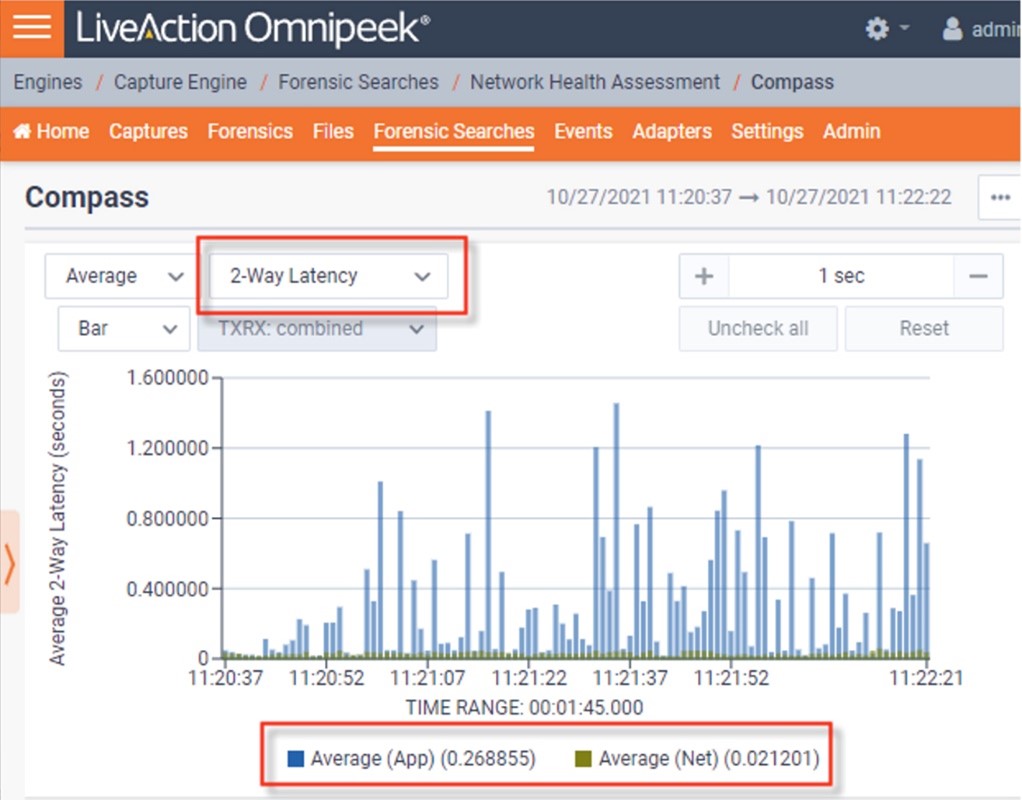
二、停机时间
没有冗余的云提供商或将数据存储在私有云设置中会使您更容易受到服务中断的影响。
1、单点云故障
就私有云而言,服务器位于一个位置,这使得网络更容易受到恶意软件、电涌、与天气相关的灾难或硬件故障的影响。这种冗余的缺乏造成了多个容易发生故障的弱点。

不要把所有鸡蛋放在同一个篮子里。数据中心可能因备用电源不足、冷却故障、水损坏或网络攻击而发生故障。
2、错误的云计划规模
云架构中停机的另一个原因是资源不足以处理峰值用户负载。没有预见到容量饱和的组织可能签署了错误大小的云存储计划并达到了阈值。
预测云消耗比许多组织预期的更加困难。要成功实现基于消费的应用程序,需要了解应用程序迁移到云后的使用模式。
三、数据丢失
1、覆盖数据
数据可能会被软件更新、批量上传、用户协作项目或第三方应用程序覆盖。
2、攻击
从上次成功备份到攻击者渗透之间的数据存在丢失、删除或损坏的风险。
这些数据也可能在勒索软件攻击中被窃取并勒索赎金。即使备份策略到位,组织也可能选择支付赎金,而不是将敏感数据泄露出去。
虽然备份允许恢复应用程序的原始状态,但组织仍然可能会因备份之间发生的几个小时的工作损失而遭受损失。我们建议在不同的地理位置至少进行两次备份,以防第一个失败。
3、用户错误
用户可能会意外删除或更改他们有权访问以进行协作的文件。变化会产生未知的影响。例如,更改虚拟机大小会破坏本地数据。用户还可能搞砸灾难恢复计划并无意中导致数据丢失。
四、应用程序的互操作性
1、伪装的云应用程序
云性能不佳的主要原因之一是应用程序不兼容。数据并不总是可以跨网络架构移植,并且许多声称具有云选项的应用程序并不是为云平台设计的。这些应用程序可能需要重写代码才能在云生态系统中更好地执行。
您的云应用程序可能是伪装的固件应用程序吗?

2、有限的云集成应用程序
另一个考虑因素是应用程序与一个云供应商集成,但没有为其他云平台构建集成。这使得数据传输难以完成。
3、意外的资源消耗
另一种可能性是没有充分规划资源来支持应用程序。了解每个云托管应用程序的带宽要求非常重要,以便在启动之前进行适当的容量规划。
五、故障排除/管理问题
1、能见度
将数据从本地环境移动到云端可能意味着牺牲网络和应用程序流量的可见性。由于服务器是虚拟的,因此监视和预测数据存储和处理位置的性能和安全性变得具有挑战性。
2、意外情况
云环境可能会快速变化,组织必须在几乎没有通知的情况下适应这些更新,或者尝试执行回滚,这会占用大量资源,并且需要另一个离线期,从而影响性能。
3、工具蔓延
发生这种情况的某些情况可能是在具有多个故障排除工具的多云环境中,这使得故障排除速度更慢且更容易出错。
4、复杂网络
当分阶段云迁移到位、一些应用程序位于云中、以及一些应用程序在本地运行时,也可能会出现故障排除问题。这种多样化的架构可能会使监控问题难以查明。
5、云监控以优化性能
转向多云和混合云基础设施的好处是不可否认的
- 降低供应商锁定的风险
- 通过调度基于地理位置的工作负载来控制成本
- 享受不同云提供商的最佳功能
然而,多重、混合和公共云解决方案通常缺乏 NetOps 和 CloudOps 成功管理基础设施所需的可见性水平。这就是LiveAction出现的原因。
虹科推荐
虹科网络性能可见性解决方案
LiveAction是未来。我们的NPM平台以最广泛的遥测阵列(包括API、IPFIX、SNMP轮询和数据包)胜过其他网络监控工具。LiveAction提供监控和警报,覆盖网络运营和SecOps两方面。我们通过任何网络配置(多云、混合、远程、WiFi或WAN)识别流量异常和安全威胁。
虹科提供LiveAction网络性能可见性解决方案。该方案提供以下服务:
完整的网络和应用可见性
LiveAction简化了企业级应用和网络数据的收集、关联和展示,使其成为网络管理团队的可操作数据。简单易用的界面允许团队从全局视图出发,深入到一个位置、一个单跳,甚至一个单独的数据包。
降低网络运营成本
通过LiveAction的统一平台,企业能够消除操作多个网络管理工具的成本和复杂性,减少解决简单和复杂问题的平均时间,并通过利用自动报告节省记录网络状态的时间。
确保网络符合业务目标
LiveAction为企业提供了网络满足业务目标的信心,提供全面的网络可视性,以便做出更好的决策,并降低网络运营的整体成本。

扫码加入“虹科网络安全交流群”或关注“虹科网络安全”微信公众号,及时获取更多技术干货和应用案例。

联系我们

联系我们

