.png)
一段时间以来,我们一直在研究如何以一种简单有效的方式将系统监控和网络监控结合起来。2014年,我们对Sysdig进行了一些实验,最近,由于有了eBPF,我们对我们的工作进行了改进,以利用该技术并能够监控容器化环境。几个月前,我们已经展示了如何仅通过利用linux操作系统的某些功能,甚至不查看流量数据包,就可以检测,计数和衡量在特定主机上发生的网络活动。我们的开创性著作已发表在论文“使用eBPF结合系统可见性和安全性”。此后,我们在FOSDEM 2019上发表了“使用BPF合并系统和网络监视”的演讲,并与InfluxDB的朋友共同撰写了文章“容器时代的IT监视:进入eBPF可观察性”,除此之后还有其他活动。
在本文中,我们想向您展示如何开始使用容器和网络可见性,也就是说,你需要什么工具才能让新的奇特的指标直接交付给你的InfluxDB实例,这些指标将帮助你观察、理解和排除容器环境的故障。本质上这是一份指南,重点介绍了将系统和网络监视结合起来所需安装和运行的工具。
所需工具
需要3个轻量级工具,分别是:
nprobe-agent
以前叫做nProbe Mini,是一个小型应用程序,负责执行系统自省。如果你喜欢纯开源的解决方案(但功能有限),可以看看libebpfflow。
ntopng
一个可视化工具,它从nprobe-agent接收自省数据,并对其进行切片或分割,以产生指标并将其发送到InfluxDB。本文假设你使用的是在本博文发表时最新版本的ntopng。
InfluxDB
流行的时许数据库,用来存储ntopng产生的指标。
下图右上角部分以图形方式展示了它们是如何一起工作的。图片的其他部分也显示了它们与整个ntop可见性生态系统的关系。
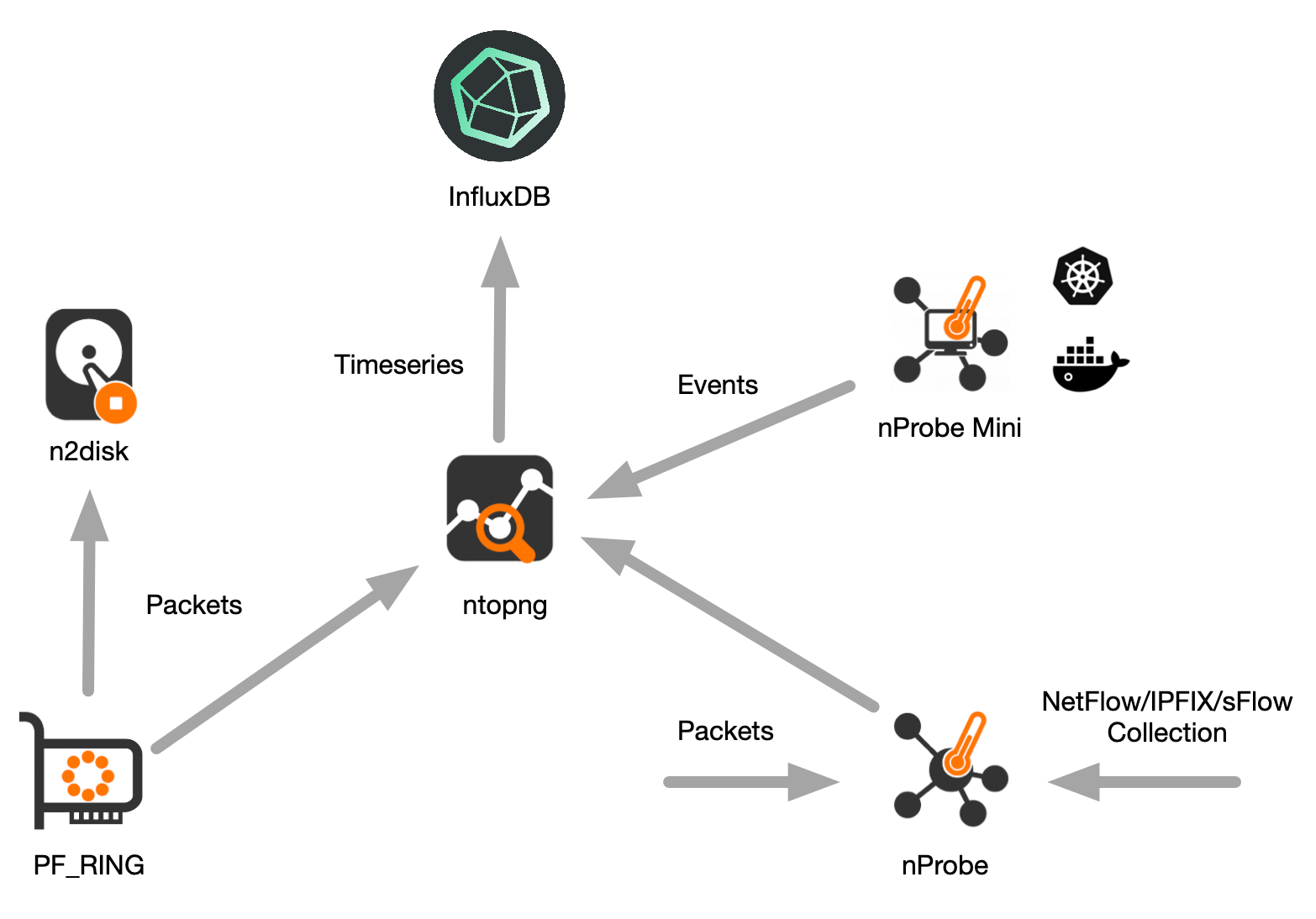
这些工具可以在同一主机上运行,也可以在三个不同的物理上独立的主机上运行,这并不重要,因为它们可以通过网络互相通信。为简单起见,在本文中,我们假定工具已安装在同一主机上运行。
安装
nProbe-agent和ntopng是由ntop发布,详细安装指南可联系虹科。
InfluxDB的安装说明可在https://docs.influxdata.com/influxdb/latest/introduction/installation/找到。
配置
要配置nprobe-agent,请将其默认配置文件复制到:
/etc/nprobe-agent/nprobe-agent.conf
$ sudo cp /etc/nprobe-agent/nprobe-agent.conf.example /etc/nprobe-agent/nprobe-agent.conf
默认的配置文件中包含了”/ etc / nprobe-agent / nprobe-agent.conf “,它指示nProbe-agent在localhost端口1234上导出内省数据。由于我们希望ntopng使用这些数据,我们必须在ntopng配置文件“/etc/ntopng/ntopng.conf”中添加“-i=tcp://*:1234c”,这样它就会监听1234端口上的传入数据。
现在配置已经完成,我们可以安全地启动我们的工具,如下所示
$ systemctl restart ntopng $ systemctl restart nprobe-agent
最后一步是告诉ntopng将指标导出到InfluxDB,这主要包括按照文档中所述更改首选项。
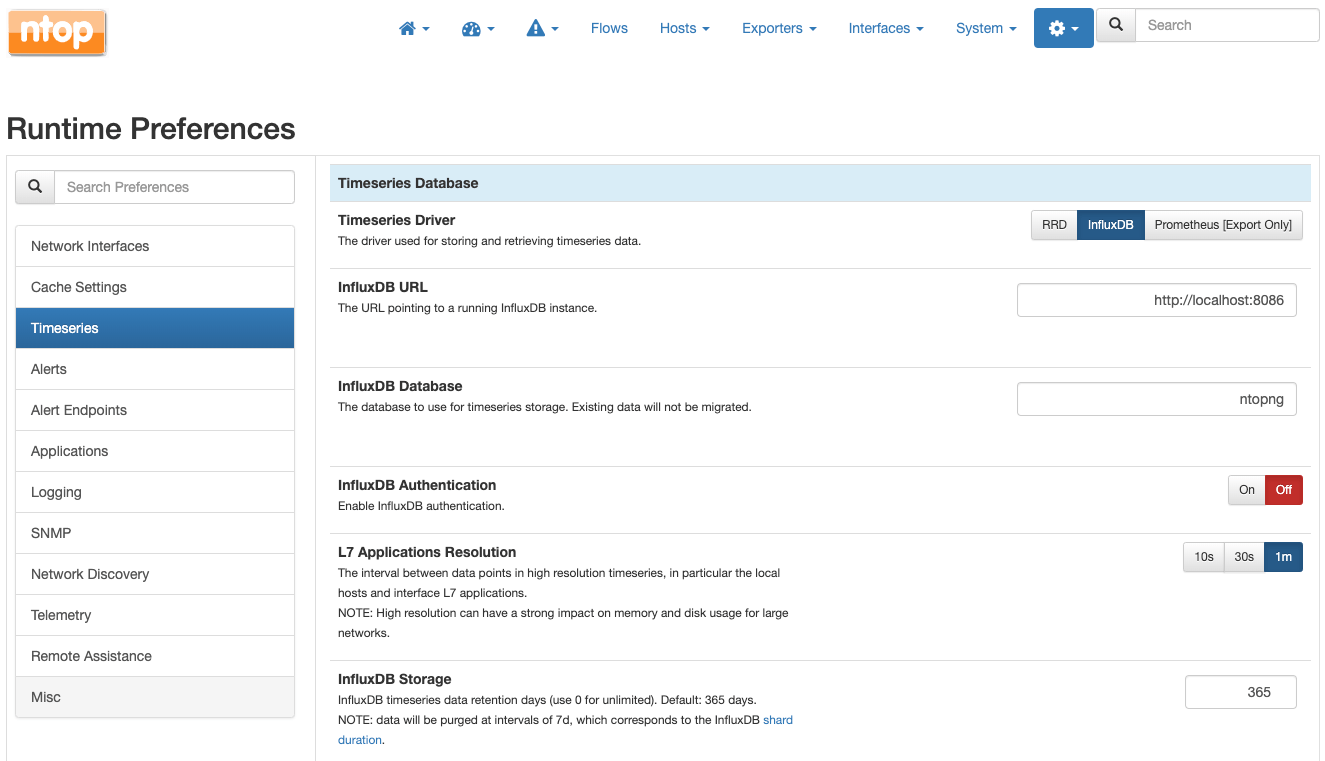
获得license
nprobe-agent需要许可才能工作,如果没有许可证,它将在全功能演示模式下工作,但只能工作5分钟。ntopng不需要许可,但如果要使用专业版或者企业版功能,就需要许可。同样,InfluxDB有可以在没有许可下工作,也有企业版可选。
指标指标指标!
由于现在所有的工具都在一起工作,你将开始看到所有发生在被监控主机上的网络通信,包括用户、进程、pods、容器、往返时间等信息。我们已经在之前的文章《系统自省网络和容器可见性:本系列快速入门指南》中讨论了如何在ntopng中浏览这些丰富的信息。
在本文中,我们将重点放在由ntopng生成并插入InfluxDB中的指标。这些指标不仅由ntopng产生,而且也由ntopng中消耗。实际上,ntopng透明地查询InfluxDB以生成您在浏览其图形用户界面时将看到的任何图表。
等等,但是如果您已经有了仪表盘解决方案,例如Grafana或Chronograf。那么,这很完美,它们将无缝运行。那你不一定需要用到ntopng图形用户界面。你可以自由地使用你最喜欢的解决方案,只需将它连接到InfluxDB,InfluxDB可以安全地存储指标,并将很乐意为它们服务–InfluxDB为Grafana和Chronograf实现了开箱即用的数据源插件。
让我们暂时回到ntopng图形用户界面,看看通过(透明地)查询InfluxDB指标生成的一些图表。
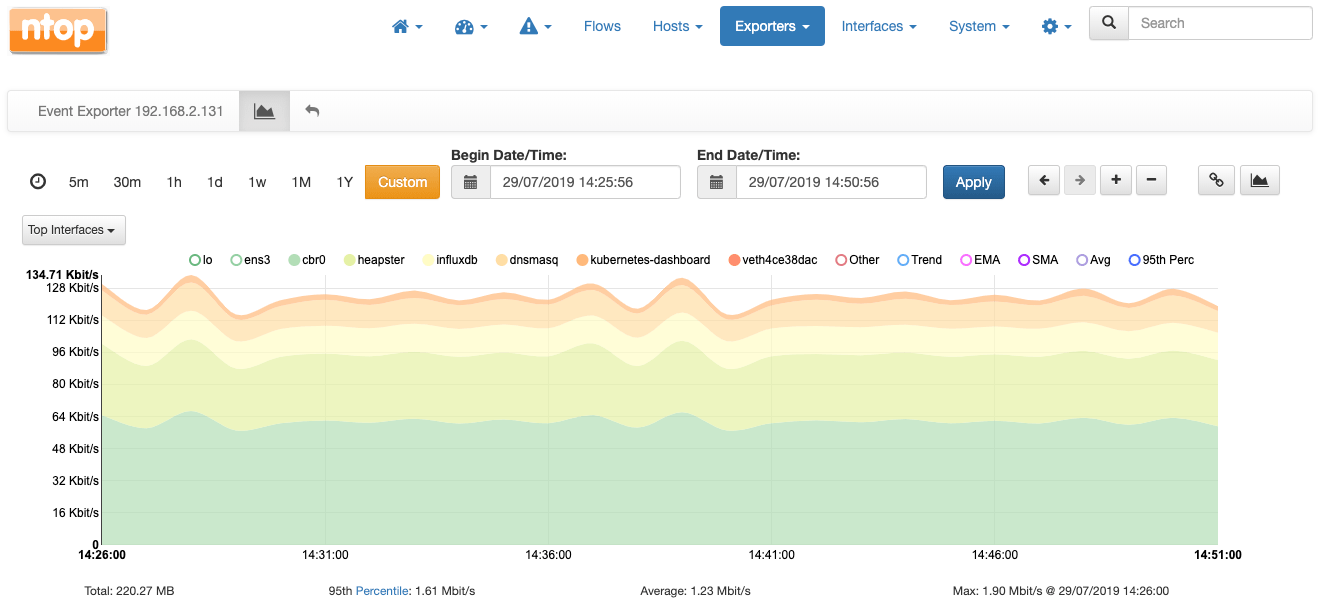
下面是主机上所有网络接口流量的叠加图。接口有物理的,也有虚拟的(比如看到v ETH ……它代表虚拟以太网…)。
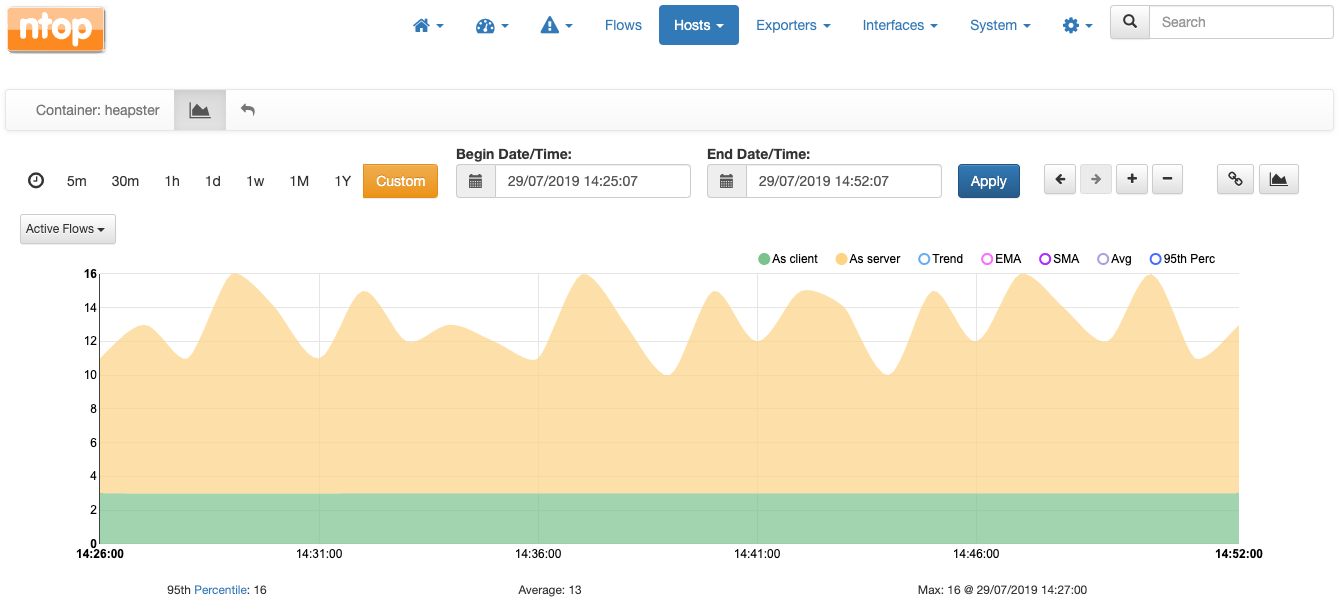
这是一张图表,它告诉了某个容器(命名为heapster)在一段时间内作为客户端和服务器活跃的活动流(即网络通信)数量。
对于同一个heapster容器,可以用毫秒为单位绘制一段时间内的平均往返时间。
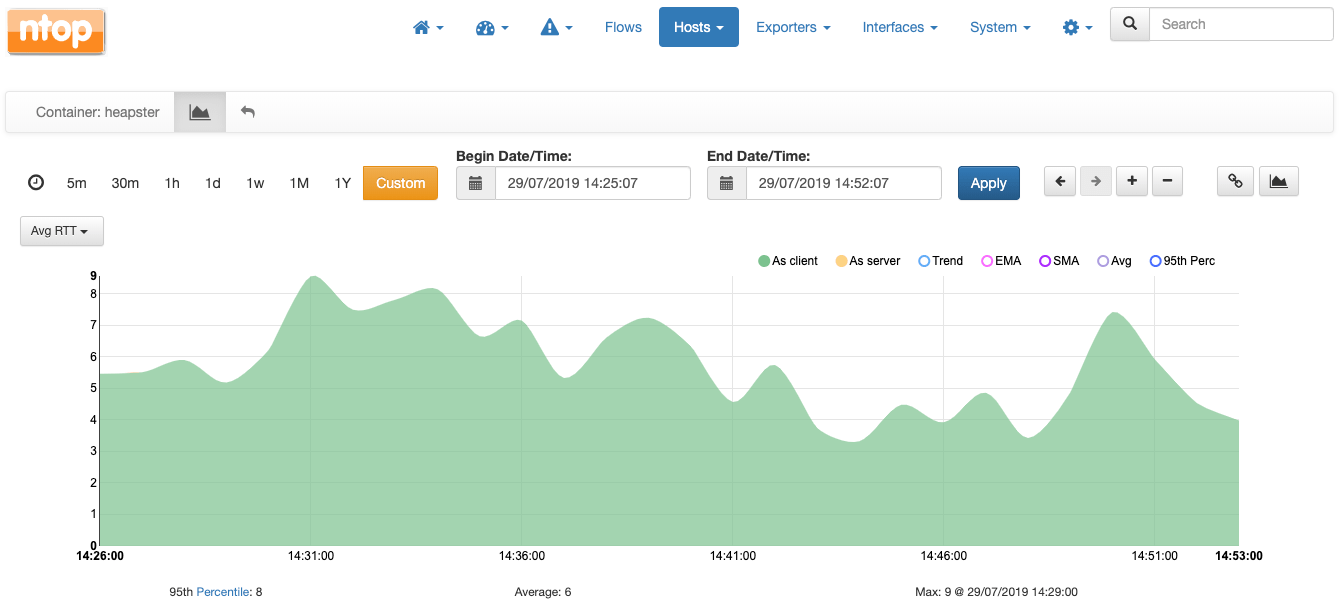
Pod级别也提供图标,其中值是pod中容器所有容器的平均值。例如,下面是pod heapster平均往返时间的图表:
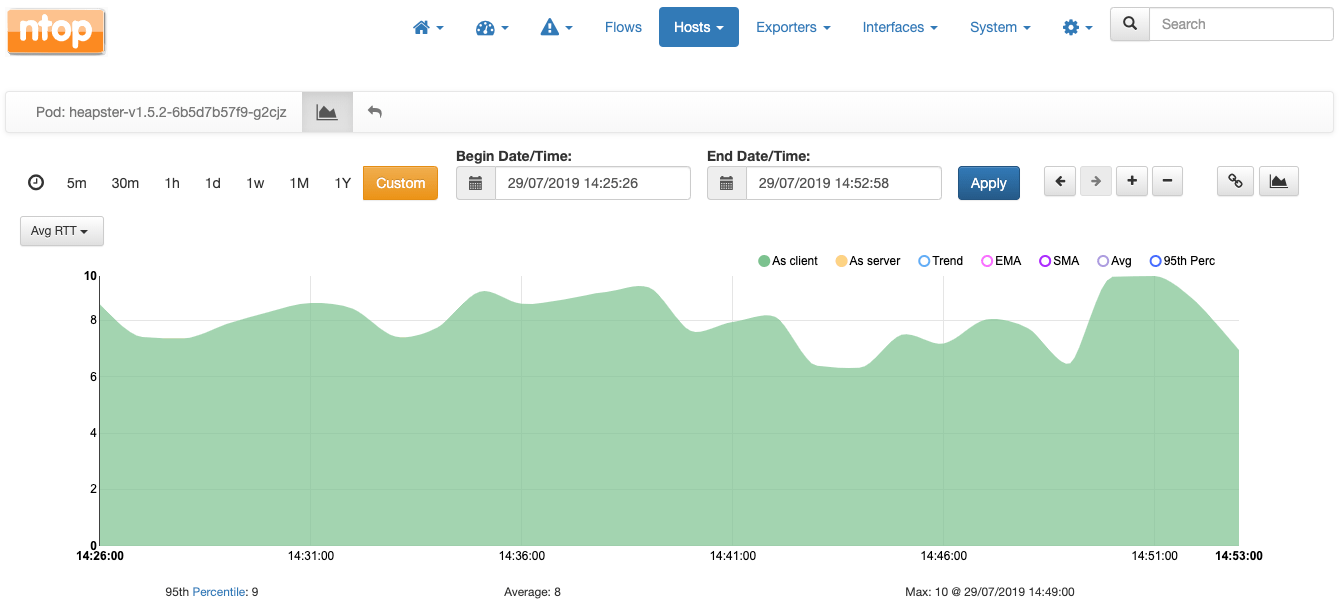
同样,上面显示的所有图表都可以通过任何其他仪表板解决方案获得,不一定是使用ntopng。
详细指标
让我们仔细看看ntopng推送到InfluxDB中的指标。此处提供了详细的指标列表。关于容器可见性,值得一提的是:
- 每个容器和POD的流的数量
- 每个容器和POD的RTT / RTT差异
- 每个POD的容器数
一旦进入InfluxDB,每个指标的值都会定期写入数据库,成为一个时间序列。接下来,我们将讨论这些指标的细节以及它们是如何存储在InfluxDB中的。
名称name
所有的指标都由一个名称。这个名称也就是InfluxDB中所说的变量。ntopng使用的惯例是<prefix>:<suffix>来命名指标。
- <prefix>是指标的主题,例如主机是容器还是接口
- <suffix>是指标代表的内容,例如:流量、往返时间或流的数量
名称示例:
- pod:rtt
- pod:num_flows
- container:num_flows
- host:ndpi
标签tags
每个指标都有一个或多个相关的标签。标签是用来过滤指标的。ntopng使用标签来丰富指标,包括接口的名称或标识符、主机的IP地址、POD或容器的标识符等。
标签的例子:
- ifid=0
- subnet=192.168.2.0/24
- container=89b0acbdba4b
- pod=heapster-v1.5.2-6b5d7b57f9-g2cjz
分辨率Resolution
类型type
指标有2种类型,即gauge和counter。
- counter是指随时间增加的指标,例如某个网络接口的流量。
- guage是某个时间点的活动流或活动主机的数量,可以是任何值而没有任何限制。
该文档指出了所生成的每个指标的类型。
例子
现在,我们了解了指标背后的细节,可以使用influxDB cli influx执行一些查询,就可以知道怎么简单地进行查询和操作指标。
先连接到InfluxDB,选择数据库ntopng:
$ influx -precision rfc3339 Connected to http://localhost:8086 version 1.7.4 InfluxDB shell version: 1.7.4 Enter an InfluxQL query > use ntopng Using database ntopng >
要列出涉及一个容器的所有测量值,我们可以做如下操作:
> show measurements with measurement =~ /^container*/ name: measurements name ---- container:num_flows container:rtt container:rtt_variance >
我们有3个测量值(3个指标),一个是流的数量,另一个是往返时间及其方差。
要选择container:num_flows的10个最新指标,我们可以这样做:
> select * from "container:num_flows" order by time desc limit 10 name: container:num_flows time as_client as_server container ifid ---- --------- --------- --------- ---- 2019-07-29T15:42:00Z 1 11 f427db2c87ac 6 2019-07-29T15:42:00Z 1 0 0a7f0bfa1a2b 6 2019-07-29T15:42:00Z 0 2 7c983b788320 6 2019-07-29T15:42:00Z 4 48 4a32234f6c35 6 2019-07-29T15:42:00Z 2 0 ceaa16daddd5 6 2019-07-29T15:42:00Z 138 34 1edb6c16e3d2 6 2019-07-29T15:42:00Z 19 121 f1e6f2b128e9 6 2019-07-29T15:42:00Z 1 0 a2a9c82c759f 6 2019-07-29T15:42:00Z 3 12 8a74af30d974 6 2019-07-29T15:41:00Z 1 0 a2a9c82c759f 6 >
我们看到,这里有多个容器。要过滤某个容器的结果,我们可以使用容器标签,如下所示
> select * from "container:num_flows" where "container" = '1edb6c16e3d2' order by time desc limit 10 name: container:num_flows time as_client as_server container ifid ---- --------- --------- --------- ---- 2019-07-29T15:44:00Z 136 24 1edb6c16e3d2 6 2019-07-29T15:43:00Z 142 40 1edb6c16e3d2 6 2019-07-29T15:42:00Z 138 34 1edb6c16e3d2 6 2019-07-29T15:41:00Z 142 28 1edb6c16e3d2 6 2019-07-29T15:40:00Z 140 21 1edb6c16e3d2 6 2019-07-29T15:39:00Z 139 38 1edb6c16e3d2 6 2019-07-29T15:38:00Z 136 23 1edb6c16e3d2 6 2019-07-29T15:37:00Z 132 36 1edb6c16e3d2 6 2019-07-29T15:36:00Z 137 21 1edb6c16e3d2 6 2019-07-29T15:35:00Z 143 26 1edb6c16e3d2 6 >
以上就是给您提供的开始使用InfluxDB和系统自检的基础知识。
本文摘自ntop,写于2019年8月1日



